mysql数据库如何分表 时间: 2020-03-25 17:49 分类: 猿码 热度: 8508°C 评论 之前的教程《[如何处理高并发流量问题](https://blog.gaomeluo.com/archives/chulibingfa/ "如何处理高并发流量问题")》中提到需要对数据库进行优化。 数据库的优化总结为以下三点: 《[mysql数据库如何分表](https://blog.gaomeluo.com/archives/sjkfb/ "mysql数据库如何分表")》 《[如何实现数据库读写分离](https://blog.gaomeluo.com/archives/sjkdxfl/ "如何实现数据库读写分离")》 《[mysql建表并创建索引](https://blog.gaomeluo.com/archives/sjkcjsy/ "mysql建表并创建索引")》 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,很有可能会死在那儿了。 所以,分表的目的就在于此,减小数据库的负担,缩短查询时间。 ### 一、先说不麻烦的。 还是那句话,没有钱解决不了的事,如果有,那一定是钱不够。 阿里云数据库RDS就不用自己分表,只要购买 [HybridDB for MySQL数据库](http://iil.ink/hybriddb "HybridDB for MySQL数据库") 即可。 > **参考官方解答:** > 您无需自己做分表,分布式云数据库HybridDB for MySQL高度兼容MySQL协议,若您有分布式需求,只要购买HybridDB for MySQL数据库即可,详情请参见 [云数据库HybridDB for MySQL](http://iil.ink/hybriddb "云数据库HybridDB for MySQL") 产品介绍。 而腾讯云的是这么解答的 > **云数据库会帮我做分库分表吗?** > 因为分库分表的标准和业务逻辑相关,所以云数据库不会帮业务做分库分表。 所以,还是建议使用阿里云的数据库产品。能用钱解决的问题尽量别耽误时间。如果你非要节省这些费用或者是数据库产品不支持分表,请接着往下看。 ###二、再说麻烦的 麻烦的肯定需要自己手动操作,还要承担一定的风险。 我们先来跟着教程来操作一遍。 #### 1、创建一个完整表存储着所有的成员信息 create table member( id bigint auto_increment primary key, name varchar(20), sex tinyint not null default '0' )engine=myisam default charset=utf8 auto_increment=1; 加入点数据: insert into member(id,name,sex) values (1,'jacson','0'); insert into member(name,sex) select name,sex from member; 第二条语句多执行几次就有了很多数据。 #### 2、下面我们进行分表: 这里我们分两个表tb_member1,tb_member2 DROP table IF EXISTS tb_member1; create table tb_member1( id bigint primary key auto_increment , name varchar(20), sex tinyint not null default '0' )ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; DROP table IF EXISTS tb_member2; create table tb_member2( id bigint primary key auto_increment , name varchar(20), sex tinyint not null default '0' )ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; //创建tb_member2也可以用下面的语句 create table tb_member2 like tb_member1; #### 3、创建主表tb_member DROP table IF EXISTS tb_member; create table tb_member( id bigint primary key auto_increment , name varchar(20), sex tinyint not null default '0' )ENGINE=MERGE UNION=(tb_member1,tb_member2) INSERT_METHOD=LAST CHARSET=utf8 AUTO_INCREMENT=1 ; 查看一下tb_member表的结构:desc tb_member; 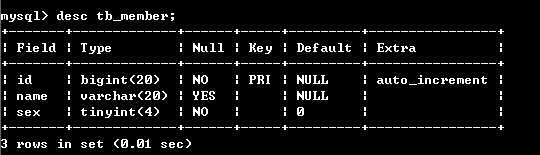 #### 4、接下来,我们把数据分到两个分表中去: insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0; insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1; 查看一下主表的数据:select * from tb_member; 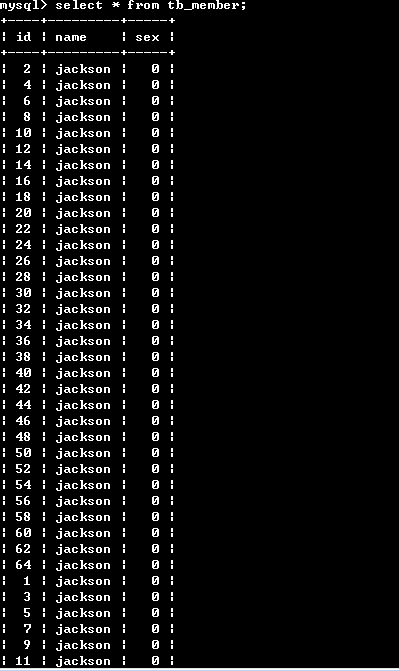 **注意:**总表只是一个外壳,存取数据发生在一个一个的分表里面。 **ps:创建主表时可能会出现下面的错误:** `ERROR 1168 (HY000): Unable to open underlying table which is differently defined or of non-MyISAM type or doesn't exist` 若遇到上面这种错误,一般从两方面来排查:(从这两方面一般可以解决这个问题,本人也遇到了。) - 查看上面的分表数据库引擎是不是MyISAM. - 查看分表与指标的字段定义是否一致。 #### 分表的大概过程和步骤就是这样的,下面我们来看看分表的算法实现: 假设现在有一个应用系统可能会有100亿的用户量,另外一个表一般存储量在不超过100万的时候基本能保持良好性能,计算下来,我们需要1万张表,即分表为1万个表。 我们可以设计成:user_0~user_9999 在用户表里面我们有唯一的标示是用户id,我们尅设计一个小算法来实现用户id与访问表名的对应: function getTable($id) { return 'user_'.sprintf('%d',($id >>20)); } **解释一下:** ($id >> 20)表示将向右移位20位,(向右移动一位标示减少一半),printf('%d',$data)标示将数据按照十进制输出。 即id为1~1048575(2的20次幂-1)时均访问user_0,1048576~2097152时访问user_1,以此类推..... 那么问题来了,如果用户更多怎么办,现在需要一个可扩展的方法: function getTable($id,$bit,$seed){ return 'user_'.sprintf('%0{$bit}d',($id >> $seed)); } 其中:$id为用户id,$bit标示表后缀的位数,$seed表示要移位的位数即:单个表能存储的记录条数。 这样就可以任意分表了。 ### 总结: 其实上面我们介绍的是水平分表的实施方法,还存在另一种方法叫做:**垂直分表** **垂直分表:** 举例说明,在一个博客系统中,文章标题,作者,分类,创建时间等,是变化频率慢,查询次数多,而且最好有很好的实时性的数据,我们把它叫做冷数据。 而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。 我们进行纵向分表后: - 存储引擎的使用不同,冷数据使用MyIsam 可以有更好的查询数据。活跃数据,可以使用Innodb ,可以有更好的更新速度。 - 对冷数据进行更多的从库配置,因为更多的操作是查询,这样来加快查询速度。对热数据,可以相对有更多的主库的横向分表处理。 - 对于一些特殊的活跃数据,也可以考虑使用memcache ,redis之类的缓存,等累计到一定量再去更新数据库. 标签: 数据库

评论已关闭